These are notes on implementing a very simple LRU cache for my realtime image converting microservice imgproxy-lite.
In short, the 100 most recently accessed objects are kept on a ceph-filesystem rwx pvc. When object 101 is requested, the oldest (via atime) object is deleted.
For demonstration, i’ll first load up the cache directory with 100 files:
cd artifacts
for i in $(seq 1 100); do touch $(uuidgen) ; done
Lets look at the prune functioning. The messages are in kind of a weird order, but we see that q=44 results in a miss, therefore it is stored and the oldest object pruned; and the two subsequent requests are hits.
cache miss
artifacts/1455a170-6a8e-4b4c-8ed9-b06e65ce3907 pruned
converting took 0.08199381828308105
127.0.0.1 - - [04/Nov/2024 22:03:21] "GET /?img=main.jpg&q=44 HTTP/1.1" 200 -
cache hit
127.0.0.1 - - [04/Nov/2024 22:03:27] "GET /?img=main.jpg&q=44 HTTP/1.1" 200 -
cache hit
127.0.0.1 - - [04/Nov/2024 22:03:28] "GET /?img=main.jpg&q=44 HTTP/1.1" 200 -
With that in place, theres a new issue - since these are deployed as a stateless Deployment, we will get cache misses for every pod behind the loadbalancer before we start getting hits:
imgproxy-lite-b5577c668-vjsxl imgproxy-lite cache miss
imgproxy-lite-b5577c668-vjsxl imgproxy-lite converting took 0.2641286849975586
imgproxy-lite-b5577c668-vjsxl imgproxy-lite 10.42.1.2 - - [05/Nov/2024 17:05:29] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-b5577c668-mxnt9 imgproxy-lite cache miss
imgproxy-lite-b5577c668-mxnt9 imgproxy-lite converting took 0.25351381301879883
imgproxy-lite-b5577c668-mxnt9 imgproxy-lite 10.42.1.2 - - [05/Nov/2024 17:05:35] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-b5577c668-cbt5q imgproxy-lite cache miss
imgproxy-lite-b5577c668-cbt5q imgproxy-lite converting took 0.2776064872741699
imgproxy-lite-b5577c668-cbt5q imgproxy-lite 10.42.1.2 - - [05/Nov/2024 17:05:36] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-b5577c668-xsvg2 imgproxy-lite cache miss
imgproxy-lite-b5577c668-xsvg2 imgproxy-lite converting took 0.25191450119018555
imgproxy-lite-b5577c668-xsvg2 imgproxy-lite 10.42.1.2 - - [05/Nov/2024 17:05:36] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-b5577c668-52c4h imgproxy-lite cache miss
imgproxy-lite-b5577c668-52c4h imgproxy-lite converting took 0.25045228004455566
imgproxy-lite-b5577c668-52c4h imgproxy-lite 10.42.1.2 - - [05/Nov/2024 17:05:37] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-b5577c668-vjsxl imgproxy-lite cache hit
imgproxy-lite-b5577c668-vjsxl imgproxy-lite 10.42.1.2 - - [05/Nov/2024 17:05:37] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-b5577c668-mxnt9 imgproxy-lite cache hit
imgproxy-lite-b5577c668-mxnt9 imgproxy-lite 10.42.1.2 - - [05/Nov/2024 17:05:38] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-b5577c668-cbt5q imgproxy-lite cache hit
imgproxy-lite-b5577c668-cbt5q imgproxy-lite 10.42.1.2 - - [05/Nov/2024 17:05:39] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
We need a way for them to share the cache artifacts.
To address this I put the artifacts directory on a ReadWriteMany ceph-filesystem persistent volume claim:
resource "kubernetes_deployment" "imgproxy-lite" {
depends_on = [kubernetes_persistent_volume_claim.imgproxy-lite]
metadata {
name = "imgproxy-lite"
}
spec {
replicas = 5
selector {
match_labels = {
app = "imgproxy-lite"
}
}
template {
metadata {
labels = {
app = "imgproxy-lite"
}
}
spec {
container {
image = "images.local:5000/imgproxy-lite"
name = "imgproxy-lite"
env {
name = "PYTHONUNBUFFERED"
value = "1"
}
volume_mount {
mount_path = "/opt/artifacts"
name = "scratch"
}
}
volume {
name = "scratch"
persistent_volume_claim {
claim_name = "imgproxy-lite"
}
}
}
}
}
}
resource "kubernetes_persistent_volume_claim" "imgproxy-lite" {
metadata {
name = "imgproxy-lite"
}
spec {
access_modes = ["ReadWriteMany"]
resources {
requests = {
storage = "4Gi"
}
}
storage_class_name = "ceph-filesystem"
}
}
After re-deploying, we can see the cache hit ratio is improved. kw5tk converts the image and stores it on ceph, and then tnp7x, 4rg7t, and fp2tz are able to hit it:
imgproxy-lite-687dbb7dcb-kw5tk imgproxy-lite cache miss
imgproxy-lite-687dbb7dcb-kw5tk imgproxy-lite converting took 0.25154781341552734
imgproxy-lite-687dbb7dcb-kw5tk imgproxy-lite 10.42.2.68 - - [05/Nov/2024 17:50:49] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-687dbb7dcb-tnp7x imgproxy-lite cache hit
imgproxy-lite-687dbb7dcb-tnp7x imgproxy-lite 10.42.2.68 - - [05/Nov/2024 17:50:50] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-687dbb7dcb-4rg7t imgproxy-lite cache hit
imgproxy-lite-687dbb7dcb-4rg7t imgproxy-lite 10.42.2.68 - - [05/Nov/2024 17:50:50] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-687dbb7dcb-fp2tz imgproxy-lite cache hit
imgproxy-lite-687dbb7dcb-fp2tz imgproxy-lite 10.42.2.68 - - [05/Nov/2024 17:50:51] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
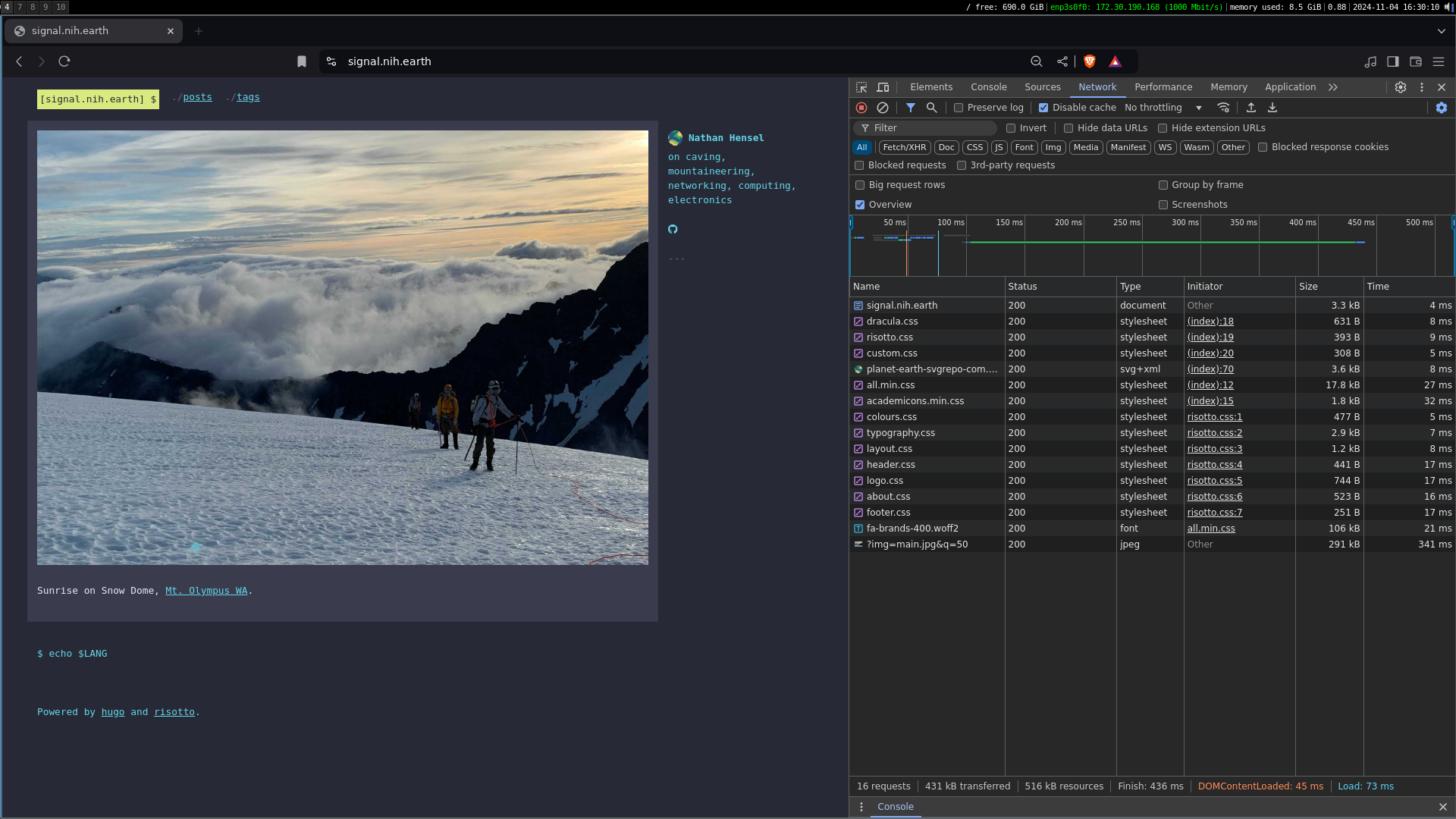
Heres the performance result of implementing caching. Heres the main page with a cache miss:
And heres the main page with a cache hit:
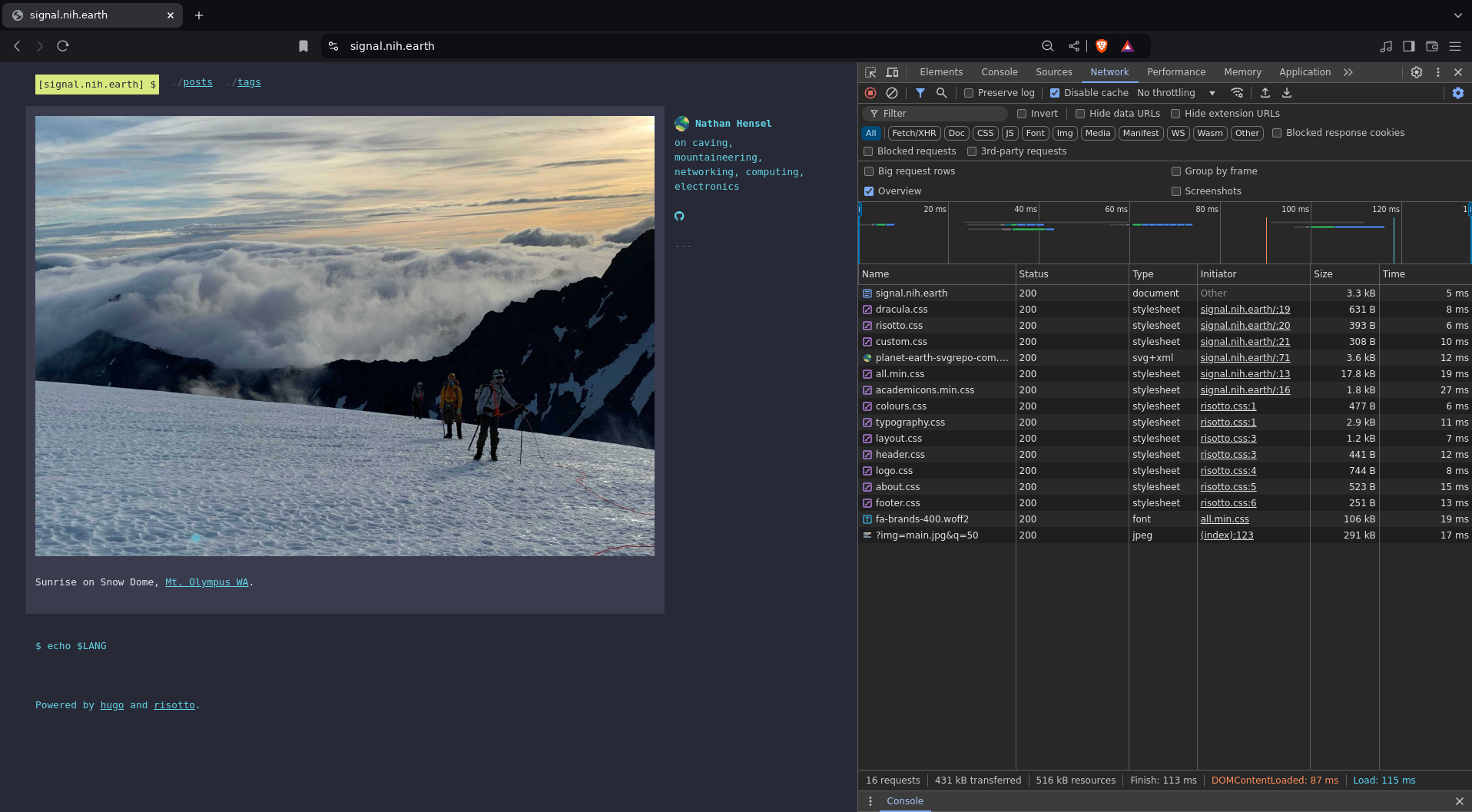
We’ve gone from 436ms to 113ms for a full page load.
Thread Safety
For the most part replicas shouldn’t conflict, as python’s open() to write will just silently truncate and re-write a file if it already exists. So in the event that two workers ‘miss’ a file at effectively the same time, but one worker beats the other to the writing phase, the second should just silently re-write it without crashing.
In the case that something goes wrong at the instant a file is being read from the cache - perhaps it happens to be the oldest object and another worker prunes it at exactly that instant - i have accounted for a number of potentially relevant exceptions. This would of course be tricky to test, so time will tell if its enough.
Likewise, the case where two workers attempt to prune an object at the same moment is accounted for.
In the event where the mountpoint is out of space the service will simply keep missing the cache, but will continue functioning:
/opt/artifacts # dd if=/dev/zero of=./memes
...
imgproxy-lite-7dcc979c99-g9m75 imgproxy-lite cache miss
imgproxy-lite-7dcc979c99-g9m75 imgproxy-lite converting took 0.26177287101745605
imgproxy-lite-7dcc979c99-g9m75 imgproxy-lite error writing cache object: [Errno 122] Quota exceeded
imgproxy-lite-7dcc979c99-g9m75 imgproxy-lite 10.42.1.2 - - [05/Nov/2024 19:58:14] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
imgproxy-lite-7dcc979c99-h4k24 imgproxy-lite cache miss
imgproxy-lite-7dcc979c99-h4k24 imgproxy-lite converting took 0.25931715965270996
imgproxy-lite-7dcc979c99-h4k24 imgproxy-lite error writing cache object: [Errno 122] Quota exceeded
imgproxy-lite-7dcc979c99-h4k24 imgproxy-lite 10.42.1.2 - - [05/Nov/2024 19:58:27] "GET /?img=main.jpg&q=50 HTTP/1.1" 200 -
Surely this isn’t perfect, but its good enough for now. In the event that a pod throws an exception because of something I didn’t foresee, oh well, there are four other pods and it will recover. We’ll debug that when the time comes. Like I said - “Minimum Viable Cache”.
