I had an issue with clock_skew occasionally blocking ceph health for unreasonable amounts of time when rebooting nodes (10+ minutes), so i set up telegaf and influx to understand the issue.
Heres the issue:
~ > kubectl -n rook-ceph exec -it deployments/rook-ceph-tools -- ceph status
cluster:
id: 3f5657ce-3017-4192-959d-37a8f1fc95f4
health: HEALTH_WARN
clock skew detected on mon.c, mon.e
services:
mon: 3 daemons, quorum b,c,e (age 16m)
mgr: b(active, since 13m), standbys: a
mds: 1/1 daemons up, 1 hot standby
ose: 3 osds: 3 up (since 15m), 3 in (since 25h)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 895 objects, 1.2 GiB
usage: 3.9 GiB used, 533 GiB / 537 GiB avail
pgs: 169 active+clean
io:
client: 938 B/s rd, 11 KiB/s wr, 1 op/s rd, 1 op/s wr
Heres the NixOS config for telegraf and chrony:
services.chrony.enable = true;
services.telegraf = {
enable = true;
extraConfig = {
outputs = {
influxdb_v2 = {
urls = ["http://10.1.2.3:8086"];
token = "asdf";
organization = "default";
bucket = "default";
};
};
inputs = {
chrony = {};
mem = {};
sensors = {};
system = {};
cpu = {
percpu = false;
};
linux_cpu = {
metrics = ["cpufreq"];
};
disk = {
mount_points = ["/"];
};
diskio = {
devices = ["{{node.boot_device}}"];
};
net = {
interfaces = ["{{node.interface}}"];
};
smart = {
use_sudo = true;
attributes = true;
};
};
};
};
systemd.services.telegraf.path = [ pkgs.lm_sensors pkgs.smartmontools pkgs.nvme-cli "/run/wrappers" ];
security.sudo.extraRules = [{
users = [ "telegraf" ];
commands = [
{ command = "${pkgs.smartmontools}/bin/smartctl"; options = [ "NOPASSWD" ]; }
{ command = "${pkgs.nvme-cli}/bin/nvme"; options = [ "NOPASSWD" ]; }
];
}];
Heres what the graph looks like when rebooting three nodes:
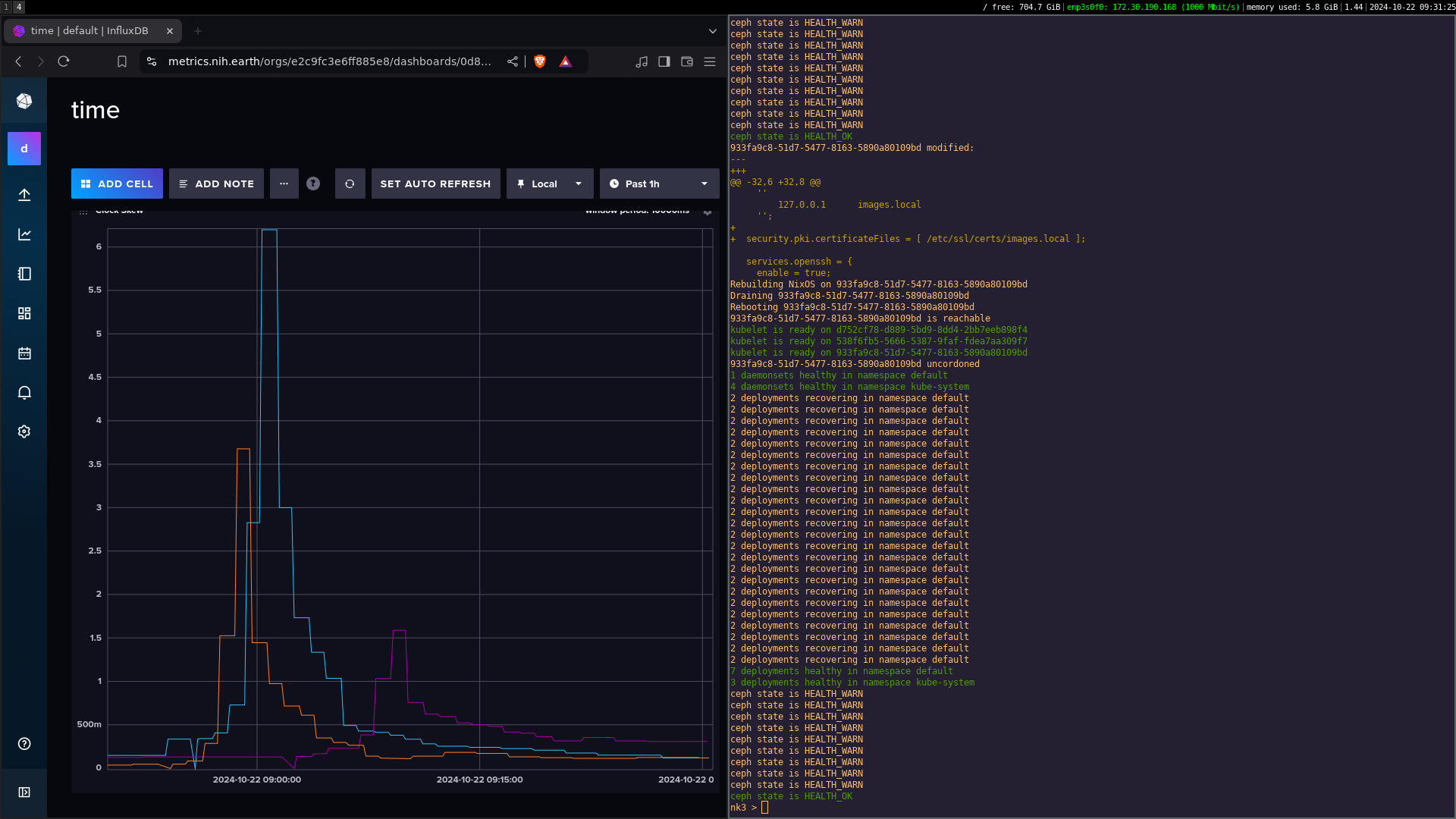
Its clear from looking at this that the tolerable skew for ceph is around one second.
Ironically, setting this up required switching from systemd-timesyncd to chrony (as the telegraf plugin exists for chrony only), and chrony seems to be faster about getting nodes back in sync after rebooting. Therefore I haven’t seen the extended 10+ minute periods of skew warning since switching.
It is interesting however to see how they wander over extended periods:
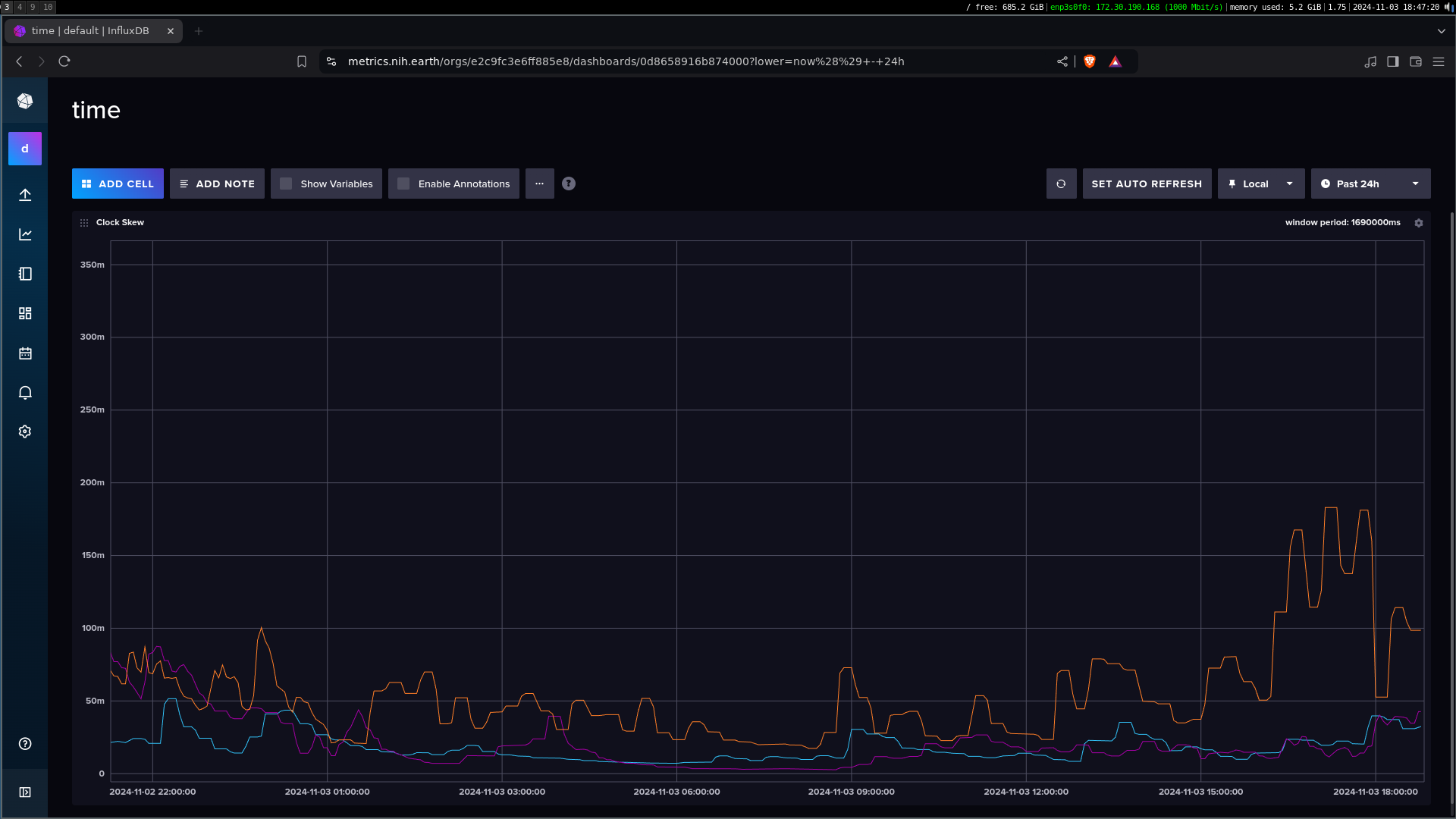
Heres a neat fact: you might wonder why they ramp up and down slowly. Why not just correct the system time immediately if its known to be wrong? Time daemons like chrony and timesyncd intentionally do their corrections by slightly speeding up and slowing down system time so to not cause impossible jumps that would scramble logs and bug out applications that trust the system. That is to say serializability is much more important than accuracy.
