This weekend’s project was what I’m calling ece, a demonstration platform for developing, running, and publishing a dbt etl project and associated kubernetes applications on ephemeral cloud infrastructure.
ece enables an isolated, self-service, fully reproducible means for running a dbt project on a cloud database, connecting kubernetes applications - and then pivoting a snapshot of the entire environment to a ‘production’ context. In short, ece wraps opentofu (formerly terraform) to recreate Everything when desired, and pulls information out of the tf state to template out connection information for dbt, kubernetes apps, etc. The repository has a sample dbt project to do some phony sql work on 10 million fabricated ‘patients’ with 10 ‘diagnoses’ each, and a pre-authenticated pgweb instance is provisioned on a kubernetes cluster for browsing the database.
The context in which this is useful is one where: a team owns an iterative etl process where the input is some sort of tabular data, transformation is performed in a database into a number of different standardized data models, and the delivereable output is one or more web applications pointed at the transformations. In such a workflow, it is easy to forsee points of contention if such a team is sharing a handful of predefined ‘dev’ and ‘production’ databases and servers - server resource contention, database to database configuration drift, server to server configuration drift, difficulty in working on multiple branches at once (kick off a build, go work on something else).
For the cost of about 3-5 minutes to create the environment at the beginning of our ‘build’ process, all these problems are solved. We can think of this as the Dockerfile model for data pipelines. There are countless positive side-affects in making these abstractions:
- we can run etl on fast, expensive instances, and immediately publish to something cheaper.
- full start to finish reproducibility.
- triviality of experimentation. we can answer questions like ‘would we benefit from more ram or more cpu’ by editing a single string in
databases.yml. - secure by default. all credentials are short lived and randomly generated every time the infrastructure is provisioned.
- no resource sharing between developers.
- ease in working on multiple branches - one can simply have the project checked out in multiple directories; each gets its own infrastructure.
- lowered operational costs. instead of simply having to guess and pick an upper-tier instance, configure it, and paying for it to sit and do nothing for the majority of its life, we can optimize for cost-per-ETL and tear things down when we’re not using them.
This work is presented on DigitalOcean infrastructure, but the approach is transferrable to any cloud provider.
implementation
python3 ece -h
usage: ece [-h] [--destroy] [--hints] [--publish]
options:
-h, --help show this help message and exit
--destroy, --cleanup delete all resources
--hints print copy-paste login and dbt commands
--publish transfer current working state to production
The default action is to enforce infrastructure state and run dbt build. Heres a full run on db-s-1vcpu-1gb:
(venv) ~/git/ephemeral_cloud_etl$ time python3 ece
OpenTofu used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
OpenTofu will perform the following actions:
# module.dev.digitalocean_database_cluster.etl will be created
+ resource "digitalocean_database_cluster" "etl" {
+ database = (known after apply)
+ engine = "pg"
+ host = (known after apply)
+ id = (known after apply)
+ name = "etl-pgsql-dev"
+ node_count = 1
+ password = (sensitive value)
+ port = (known after apply)
+ private_host = (known after apply)
+ private_network_uuid = (known after apply)
+ private_uri = (sensitive value)
+ project_id = (known after apply)
+ region = "nyc1"
+ size = "db-s-1vcpu-1gb"
+ storage_size_mib = "20480"
+ uri = (sensitive value)
+ urn = (known after apply)
+ user = (known after apply)
+ version = "15"
}
# module.dev.digitalocean_database_db.etl will be created
+ resource "digitalocean_database_db" "etl" {
+ cluster_id = (known after apply)
+ id = (known after apply)
+ name = "dbt"
}
Plan: 2 to add, 0 to change, 0 to destroy.
module.dev.digitalocean_database_cluster.etl: Creating...
module.dev.digitalocean_database_cluster.etl: Creation complete after 3m23s [id=e440899f-f0ec-468e-a903-72186f03d72a]
module.dev.digitalocean_database_db.etl: Creating...
module.dev.digitalocean_database_db.etl: Creation complete after 2s [id=e440899f-f0ec-468e-a903-72186f03d72a/database/dbt]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
found database etl-pgsql-dev
etl-pgsql-dev-do-user-1228802-0.c.db.ondigitalocean.com ready
patients does not exist. creating...
CREATE TABLE
COPY 10000000
icd10 does not exist. creating...
CREATE TABLE
COPY 71704
providers does not exist. creating...
CREATE TABLE
COPY 8026546
diagnoses does not exist. creating...
CREATE TABLE
COPY 100000000
07:38:00 Running with dbt=1.7.1
07:38:00 Registered adapter: postgres=1.7.1
07:38:00 Unable to do partial parsing because profile has changed
07:38:01 [WARNING]: Configuration paths exist in your dbt_project.yml file which do not apply to any resources.
There are 1 unused configuration paths:
- models.etl.example
07:38:01 Found 5 models, 10 tests, 4 sources, 0 exposures, 0 metrics, 401 macros, 0 groups, 0 semantic models
07:38:01
07:38:04 Concurrency: 10 threads (target='dev')
07:38:04
07:38:04 1 of 15 START sql table model public.distinct_patients ......................... [RUN]
07:38:04 2 of 15 START sql table model public.distinct_providers ........................ [RUN]
07:38:04 3 of 15 START sql table model public.female_patients ........................... [RUN]
07:38:04 4 of 15 START sql table model public.male_patients ............................. [RUN]
07:38:04 5 of 15 START sql table model public.observed_diagnoses ........................ [RUN]
07:40:59 4 of 15 OK created sql table model public.male_patients ........................ [SELECT 4998979 in 174.57s]
07:40:59 6 of 15 START test not_null_male_patients_patid ................................ [RUN]
07:40:59 7 of 15 START test unique_male_patients_patid .................................. [RUN]
07:41:06 3 of 15 OK created sql table model public.female_patients ...................... [SELECT 5001021 in 181.57s]
07:41:06 8 of 15 START test not_null_female_patients_patid .............................. [RUN]
07:41:06 9 of 15 START test unique_female_patients_patid ................................ [RUN]
07:41:24 6 of 15 PASS not_null_male_patients_patid ...................................... [PASS in 24.86s]
07:41:52 8 of 15 PASS not_null_female_patients_patid .................................... [PASS in 46.09s]
07:43:14 7 of 15 PASS unique_male_patients_patid ........................................ [PASS in 135.09s]
07:44:26 1 of 15 OK created sql table model public.distinct_patients .................... [SELECT 10000000 in 382.29s]
07:44:26 10 of 15 START test not_null_distinct_patients_patid ........................... [RUN]
07:44:26 11 of 15 START test unique_distinct_patients_patid ............................. [RUN]
07:44:59 10 of 15 PASS not_null_distinct_patients_patid ................................. [PASS in 32.92s]
07:45:11 9 of 15 PASS unique_female_patients_patid ...................................... [PASS in 245.61s]
07:47:26 11 of 15 PASS unique_distinct_patients_patid ................................... [PASS in 179.90s]
07:53:41 2 of 15 OK created sql table model public.distinct_providers ................... [SELECT 6104471 in 937.16s]
07:53:41 12 of 15 START test not_null_distinct_providers_npi ............................ [RUN]
07:53:41 13 of 15 START test unique_distinct_providers_npi .............................. [RUN]
07:53:56 12 of 15 PASS not_null_distinct_providers_npi .................................. [PASS in 14.50s]
07:54:21 13 of 15 PASS unique_distinct_providers_npi .................................... [PASS in 39.74s]
07:54:23 5 of 15 OK created sql table model public.observed_diagnoses ................... [SELECT 71704 in 979.30s]
07:54:23 14 of 15 START test not_null_observed_diagnoses_dx_code ........................ [RUN]
07:54:23 15 of 15 START test unique_observed_diagnoses_dx_code .......................... [RUN]
07:54:24 14 of 15 PASS not_null_observed_diagnoses_dx_code .............................. [PASS in 0.50s]
07:54:24 15 of 15 PASS unique_observed_diagnoses_dx_code ................................ [PASS in 0.54s]
07:54:24
07:54:24 Finished running 5 table models, 10 tests in 0 hours 16 minutes and 23.35 seconds (983.35s).
07:54:24
07:54:24 Completed successfully
07:54:24
07:54:24 Done. PASS=15 WARN=0 ERROR=0 SKIP=0 TOTAL=15
real 24m24.166s
user 0m13.338s
sys 0m2.136s
At any stage in the process, the user is free to use the underlying tools independently of the abstraction ece provides. For example, once the infrastructure is provisioned, one can freely cd into the dbt project at etl/ and run dbt commands as usual - we don’t literally have to destroy everything every time, but it is a non-event when we choose to.
The --hints flag generates pre-populated copy-paste command hints for various tools we may want to use on our environment (yes i pasted some passwords here. Rest assured, this infrastructure is long-gone):
(venv) ~/git/ephemeral_cloud_etl$ python3 ece --hints
module.db.random_id.context: Refreshing state... [id=uiznCQ]
module.db.digitalocean_database_cluster.etl: Refreshing state... [id=4273ad9b-a966-48e9-9eb6-20571fada70e]
module.db.digitalocean_kubernetes_cluster.data-apps: Refreshing state... [id=a85a8a04-eadf-49ee-b867-0d41a906711d]
module.db.kubernetes_deployment.pgweb: Refreshing state... [id=default/pgweb]
No changes. Your infrastructure matches the configuration.
OpenTofu has compared your real infrastructure against your configuration and found no differences, so no changes are needed.
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
found database dbt-pgsql-ba2ce709
Log into dbt-pgsql-ba2ce709 with:
PGPASSWORD=AVNS_hEICA80ZuxfdNoT2XV5 psql -h dbt-pgsql-ba2ce709-do-user-1228802-0.c.db.ondigitalocean.com -p 25060 -U doadmin -d defaultdb
See pg_activity with:
PGPASSWORD=AVNS_hEICA80ZuxfdNoT2XV5 pg_activity -h dbt-pgsql-ba2ce709-do-user-1228802-0.c.db.ondigitalocean.com -p 25060 -U doadmin -d defaultdb
Run dbt with:
dbt build --project-dir etl --profiles-dir etl
Connect to kubernetes with:
kubectl --kubeconfig kubeconfig.yml get pods
Forward frontend with:
kubectl --kubeconfig kubeconfig.yml port-forward deployment/pgweb 8081:8081
As you may have noticed, --hints simultaneously templates out ./kubeconfig.yml for use with kubectl.
Heres a resulting pgweb instance:
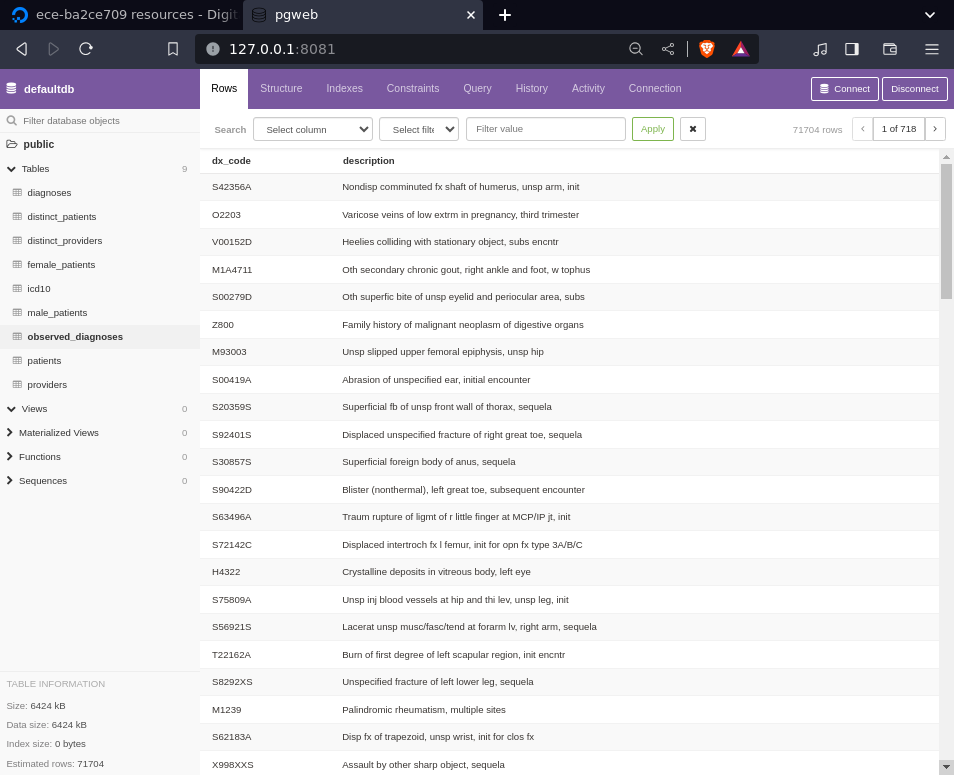
publishing to production
When we’re happy with the state of the current working environment, we can publish it to ‘production’. This doesn’t move any data, but moves the tf state itsef from our dev context to the production state under prod/. The idea here is that when working on a team, prod/ would be configured to use an external locking state provider.
In this example, we have a smaller instance tier defined for the production database, so it is simultaneously downsized in-place:
(venv) ~/git/ephemeral_cloud_etl$ python3 ece --publish
module.db.random_id.context: Refreshing state... [id=uiznCQ]
module.db.digitalocean_database_cluster.etl: Refreshing state... [id=4273ad9b-a966-48e9-9eb6-20571fada70e]
module.db.digitalocean_kubernetes_cluster.data-apps: Refreshing state... [id=a85a8a04-eadf-49ee-b867-0d41a906711d]
module.db.kubernetes_deployment.pgweb: Refreshing state... [id=default/pgweb]
No changes. Your infrastructure matches the configuration.
OpenTofu has compared your real infrastructure against your configuration and found no differences, so no changes are needed.
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
found database dbt-pgsql-ba2ce709
No changes. No objects need to be destroyed.
Either you have not created any objects yet or the existing objects were already deleted outside of OpenTofu.
Destroy complete! Resources: 0 destroyed.
module.db.random_id.context: Refreshing state... [id=uiznCQ]
module.db.digitalocean_database_cluster.etl: Refreshing state... [id=4273ad9b-a966-48e9-9eb6-20571fada70e]
module.db.digitalocean_kubernetes_cluster.data-apps: Refreshing state... [id=a85a8a04-eadf-49ee-b867-0d41a906711d]
module.db.kubernetes_deployment.pgweb: Refreshing state... [id=default/pgweb]
OpenTofu used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
~ update in-place
OpenTofu will perform the following actions:
# module.db.digitalocean_database_cluster.etl will be updated in-place
~ resource "digitalocean_database_cluster" "etl" {
id = "4273ad9b-a966-48e9-9eb6-20571fada70e"
name = "dbt-pgsql-ba2ce709"
~ size = "db-s-2vcpu-4gb" -> "db-s-1vcpu-2gb"
tags = []
# (16 unchanged attributes hidden)
}
Plan: 0 to add, 1 to change, 0 to destroy.
Do you want to perform these actions?
OpenTofu will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
module.db.digitalocean_database_cluster.etl: Modifying... [id=4273ad9b-a966-48e9-9eb6-20571fada70e]
module.db.digitalocean_database_cluster.etl: Modifications complete after 14m32s [id=4273ad9b-a966-48e9-9eb6-20571fada70e]
Apply complete! Resources: 0 added, 1 changed, 0 destroyed.
Removed module.db.random_id.context
Successfully removed 1 resource instance(s).
Removed module.db.digitalocean_database_cluster.etl
Successfully removed 1 resource instance(s).
Removed module.db.digitalocean_kubernetes_cluster.data-apps
Successfully removed 1 resource instance(s).
Removed module.db.kubernetes_deployment.pgweb
Successfully removed 1 resource instance(s).
Once published, our dev state is empty, and we’re free to run the full stack again without affecting production:
(venv) ~/git/ephemeral_cloud_etl$ tofu state list
(venv) ~/git/ephemeral_cloud_etl$
(venv) ~/git/ephemeral_cloud_etl$ tofu -chdir=prod state list
module.db.digitalocean_database_cluster.etl
module.db.digitalocean_kubernetes_cluster.data-apps
module.db.kubernetes_deployment.pgweb
module.db.random_id.context
(venv) ~/git/ephemeral_cloud_etl$ python3 ece
...
All resources are destroyed with –cleanup. (This does not include production. Once published, ece doesn’t touch production again until the next publication):
$ python3 ece --cleanup
module.dev.digitalocean_database_cluster.etl: Refreshing state... [id=530c0958-7e7d-4670-9c30-d94d631a68de]
module.dev.digitalocean_database_db.etl: Refreshing state... [id=530c0958-7e7d-4670-9c30-d94d631a68de/database/dbt]
OpenTofu used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
- destroy
OpenTofu will perform the following actions:
# module.dev.digitalocean_database_cluster.etl will be destroyed
-- diff truncated --
Plan: 0 to add, 0 to change, 2 to destroy.
module.dev.digitalocean_database_db.etl: Destroying... [id=530c0958-7e7d-4670-9c30-d94d631a68de/database/dbt]
module.dev.digitalocean_database_db.etl: Destruction complete after 12s
module.dev.digitalocean_database_cluster.etl: Destroying... [id=530c0958-7e7d-4670-9c30-d94d631a68de]
module.dev.digitalocean_database_cluster.etl: Destruction complete after 2s
Destroy complete! Resources: 2 destroyed.
optimizing for cost-per-ETL
Since the infrastructure is abstracted, it is trivial to run a few tests and optimize for real-world performance per dollar rather than simply picking ’the cheapest tier’ or ’the fastest tier’.
db-s-1vcpu-1gb basic 1 cpu $0.02535/hr:
Finished running 5 table models, 10 tests in 0 hours 16 minutes and 23.35 seconds (983.35s).
real 24m24.166s
etl alone cost $.00692
db-s-2vcpu-4gb basic 2 cpu $0.08943/hr:
Finished running 5 table models, 10 tests in 0 hours 3 minutes and 10.48 seconds (190.48s)
real 8m24.059s
etl alone cost $.00472
so1_5-2vcpu-16gb ‘storage optimized’ 2cpu $0.31619/hr:
Finished running 5 table models, 10 tests in 0 hours 4 minutes and 3.64 seconds (243.64s).
real 9m43.786s
etl alone cost $.02143, or 4.5x db-s-2vcpu-4gb!
These tests show that db-s-2vcpu-4gb is the cheapest to operate (of those tested), even coming in with a cost per ETL 68% of the bottom tier db-s-1vcpu-1gb.
Also interesting is that the significantly more expensive ‘storage optimized’ instance class clearly does not help this workload, nor does the 16gb of ram it comes with - it would be easy to assume the opposite.
Hourly rates found at https://www.digitalocean.com/pricing/managed-databases.
For what its worth, building this tool cost just $0.12 to provision and destroy 14 databases.
Here are metrics from a db-s-1vcpu-1gb run, clearly showing cpu as the most significant limitation:
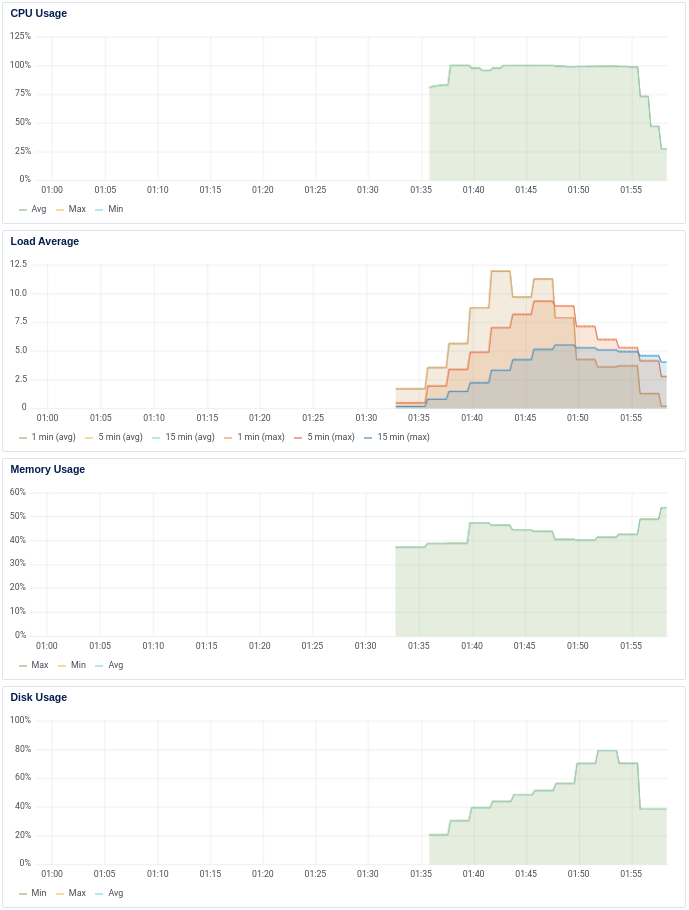
And heres a db-s-2vcpu-4gb run, showing only a brief period of ~90% cpu utilization, indicating the bottleneck is now elsewhere:
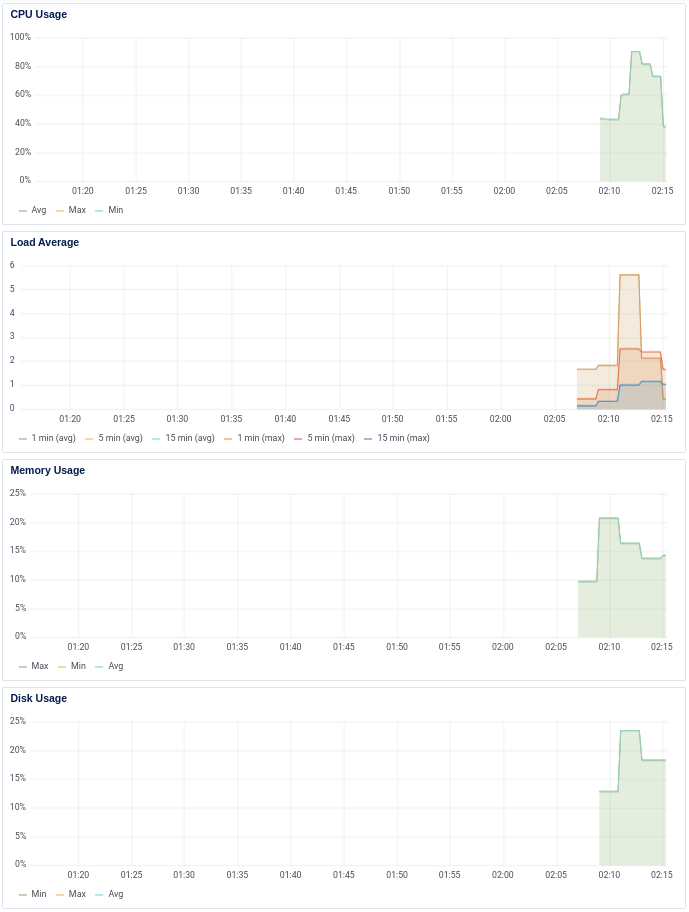
caveats
In this example project, I’m simply staging some sample data from local csvs. If dealing with TBs of data, we would of course want to stage this from something physically local to our infrastructure, like object storage.
The –publish workflow doesn’t do much other than export our tf state. IRL, we would probably also want to trigger the movement of a floating ip, dns, etc. as appropriate.
